Inhaltsverzeichnis
Eingabe der SQL-Befehle
Die Eingabe der SQL-Befehle geschieht mit [Anhängen…] bzw. [Erstellen…]
Auswahl SQL
In einer Konfiguration steuern beliebig viele SQL-Befehle (Im folgenden immer AUSWAHLSQL1, AUSWAHLSQL2 usw. genannt) die Auswahl der Teilmenge von Datensätzen aus einer Datei. Im Beispiel sollen zur Selektion des LVs alle Projekte und darunter die zu dem Projekt gehörenden LVs angezeigt werden. Zur Auswahl finden folgende Schritte statt:
| Schritt 1 | AUSWAHLSQL1: | SELECT ProjektID, Bezeichnung, Auftraggeber FROM PROJEKTE |
Dieser Befehl erzeugt die Liste aller Projekte und trägt sie in einer Baumstruktur als Knoten der ersten Ebene ein. Die erste selektierte Spalte dient der eindeutigen Zuordnung des Knotens zum Datensatz. Hier muss immer der Primärschlüssel der Tabelle gewählt werden.
Es ist sehr wichtig, dass hier eine Spalte gewählt wird, die den Datensatz eindeutig kennzeichnet.
Die Bezeichnung der Knoten kann für jede Ebene in einem Formatierungstext festgelegt werden. Für das Beispiel wird folgender Formatierungstext für die erste Ebene verwendet: [Bezeichnung], [Auftraggeber]
Es wird für jeden in Schritt 1 gefundenen Knoten das AUSWAHLSQL2 aufgerufen. AUSWAHLSQL2 lautet:
| Schritt 2 | AUSWAHLSQL2: | SELECT LVID, Bezeichnung FROM LVS WHERE ProjektID=[PROJEKTE:ProjektID] |
Jedes Mal, wenn ein Ausdruck in [ ] in den SQL Befehlen auftaucht, wird dieser Ausdruck aus dem Knoten der übergeordneten Ebene geladen. In diesem Fall der Inhalt des Feldes ProjektID aus der Tabelle PROJEKTE, der im AUSWAHLSQL1 geladen wurde.
Die gefundenen Sätze werden unter dem jeweiligen Knoten aus Schritt 1 als Unterknoten eingetragen. Wiederum dient die erste selektierte Spalte der eindeutigen Zuordnung Knoten → Datensatz. Für die zweite Ebene wird lediglich die Bezeichnung im Formatierungstext verwendet: [Bezeichnung]
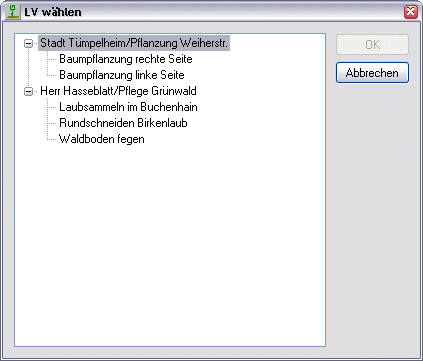
Dadurch ergibt sich im Beispiel folgende Struktur:
Bei einer flachen Struktur kann AUSWAHLSQL2 entfallen. Liefert die letzte vorhandene Ebene kein Ergebnis, so werden auch die entsprechenden Ergebnisse aus den übergeordneten Ebenen nicht angezeigt. Im Beispiel wird daher das Projekt mit der ID 15344 „Wasserpark“ nicht angezeigt.
Die Tiefe der Schachtelung ist unbegrenzt.
Besteht die anzubindende Datenbankstruktur aus mehreren Dateien (z.B. je eine Datei für ein LV) kann dies auch mit der ODBS gelöst werden. In diesem Fall muss ein Eintrag im Feld Auswahltitel im Hauptdialog erfolgen und es dürfen keine AUSWAHLSQL-Befehle definiert sein. Wird die Konfiguration dann verwendet, öffnet sich ein Dialog zur Dateiauswahl, in dem die entsprechende Datenbankdatei ausgewählt werden kann.
Die Einrichtung des Windows ODBC-Treibers ist analog der schon beschriebenen Verfahrensweise. Die Auswahl der Datei hat dabei keine Bedeutung, sondern ist nur für die Angabe des Verzeichnisses zuständig.
Gruppen SQL
Wiederum beliebig viele GRUPPENSQL-Befehle erzeugen die Baumstruktur für den Objekt-Manager. Da in unserem Beispiel maximal drei Positionsebenen vorliegen, müssen auch drei Einträge bei GRUPPENSQL erstellt werden:
| Schritt 1 | GRUPPENSQL1: | SELECT PositionID, Positionsnummer, Kurztext, GrafikID FROM POSITIONEN WHERE LVID=[LVS:LVID] AND ParentID IS null |
Die Ergebnisse aus GRUPPENSQL1 werden jetzt als Knoten erster Ebene in Massenbaumstruktur eingetragen. Die erste selektierte Spalte dient der eindeutigen Zuordnung des Knotens zum Datensatz. Hier muss immer der Primärschlüssel der Tabelle gewählt werden.
Es ist sehr wichtig, dass hier als erste selektierte Spalte eine Spalte gewählt wird, die den Datensatz eindeutig kennzeichnet.
Die Bezeichnung der Knoten kann für jede Ebene in einem Formatierungstext festgelegt werden. Für das Beispiel wird folgender Formatierungstext für alle Ebenen verwendet: [Positionsnummer] : [Kurztext]
Danach wird für jeden dieser Knoten GRUPPENSQL2 ausgeführt, der wie folgt aussieht:
| Schritt 2 | GRUPPENSQL2: | SELECT PositionID, Positionsnummer, Kurztext, GrafikID FROM POSITIONEN WHERE LVID=[LVS:LVID] AND ParentID=[POSITIONEN:PositionID] |
und zuletzt:
| Schritt 3 | GRUPPENSQL3: | SELECT PositionID, Positionsnummer, Kurztext, GrafikID FROM POSITIONEN WHERE LVID=[LVS:LVID] AND ParentID=[POSITIONEN:PositionID] |
GRUPPENSQL3 ist mit GRUPPENSQL2 identisch und liefert nur deswegen andere Ergebnisse, weil sich die Bedingung „ParentID=[POSITIONEN:PositionID]“ auf die Ergebnisse aus GRUPPENSQL2 beziehen (also nur noch die Positionen unterhalb der 2. Ebene selektiert werden).
Aus den drei SQL-Befehlen wird analog zu den AUSWAHLSQL-Befehlen eine Baumstruktur erstellt, die dann im Objekt-Manager als Massenbaum eingefügt wird. Im Beispiel sieht der Massenbaum innerhalb der Objektverwaltung wie folgt aus:
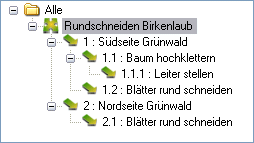
Der oberste Knoten ist das selektierte LV (in diesem Fall das LV mit der ID 17243: „Rundschneiden Birkenlaub“). Darunter wird die aus den GRUPPENSQL-Befehlen erzeugte Datensatzstruktur angelegt. Im Gegensatz zu den AUSWAHLSQL-Befehlen werden bei GRUPPENSQL auch dann Ergebnisse der höheren Ebenen angezeigt, wenn in einer tieferen Ebene kein Ergebnis mehr vorliegt. Im Beispiel sind das die Positionen 1.2, 2. und 2.1.
Die Hierarchie muss in der Datenbankstruktur vorgegeben sein, ansonsten kann nur eine Gruppenebene angezeigt werden. Dies wäre im Beispiel der Fall, wenn die Spalte ParentID fehlen würde und es nur einen GRUPPENSQL-Befehl geben würde. In diesem Fall würden alle Positionen in einer Ebene angezeigt werden.

Grafik SQL
Sofern die angebundene Datenbank Grafikinformationen enthält, können diese in der Anbindung berücksichtigt werden. Es können ein Schraffurname, die Farbe und ein Faktor ausgelesen werden. In dieser Version ist nur Schraffur möglich.
Es gibt nur einen GRAFIKSQL-Befehl für alle Ebenen.
Zur Auswertung der Grafikinformation wird für jeden gefundenen Datensatz aus allen GRUPPENSQL-Befehlen der GRAFIKSQL-Befehl aufgerufen. Das Ergebnis kann aus folgenden Spalten bestehen:
| Typ | Es wird nur das erste Zeichen des Feldes ausgewertet. Bei 0, „H“ oder „S“ wird eine Schraffur erzeugt. Bei 1 oder „B“ wird ein Block eingefügt. Bei 2, „I“, „P“ oder „G“ wird eine Grafik eingefügt. Bei 3 oder „L“ wird ein Linientyp angegeben. Groß- und Kleinschreibung wird nicht unterschieden. Voreinstellung ist 0. |
| Name | Der Name der Schraffur, des Blocks, der Grafikdatei oder des Linientyps. Standard (default) ist bei Schraffuren „SOLID“, bei Linientypen „CONTINUOUS“. Bei Block oder Grafik muss das Feld vorhanden sein um den Namen einer Datei (bei Grafik mit Erweiterung!) anzugeben. Eine Schraffur muss in der Schraffurdatei enthalten sein, oder im Suchpfad gefunden werden können. Der Linientyp muss bereits in die Zeichnung aufgenommen worden sein, oder in der Datei .LIN vorliegen. Blöcke und Grafikdateien müssen im Suchpfad gefunden werden können. Groß- und Kleinschreibung wird nicht unterschieden. |
| Farbe | Für die Farbe der Grafik gilt der Farbindex. Voreinstellung ist 7 für Weiß. Die Namen der Grundfarben bzw. die in Klammern stehenden Buchstaben „rot“ ®, „grün“ (g), „gelb“ (y), „cyan“ ©, „blau“ (b), „magenta“ (m) und „weiß“ (w); „weiss“ bzw. „schwarz“ werden ebenfalls erkannt. Groß- und Kleinschreibung wird dabei nicht unterschieden. Die Farbe „weiss“ bzw. „schwarz“ oder 7 wird in DATAflor CAD immer als Komplementärfarbe des Hintergrunds dargestellt. Bei den in Klammern stehenden Buchstaben reicht es, wenn das erste Zeichen übereinstimmt. „Yellow“ wird also als Gelb erkannt. |
| Faktor | Eine reelle oder ganze Zahl als Faktor für die Grafik. Voreinstellung ist 1,0. Bei Blöcken wird in X, Y und Z gleichmäßig skaliert. Bei Linientypen wird der Wert als Breite interpretiert. |
| Layer | Der Name des Layers, auf dem die Grafik erzeugt wird. Entfällt bei Linientypen. |
Da die Spalten in der Beispieltabelle anders heißen, müssen sie im SQL-Befehl umbenannt werden:
| Schritt 1 | GRAFIKSQL: | SELECT Bezeichnung AS Name, Farbindex AS Farbe, Faktor FROM GRAFIK WHERE GrafikID=[POSITIONEN:GrafikID] |
Der GRAFIKSQL-Befehl sollte genau einen Datensatz als Ergebnis liefern. Alle weiteren gefundenen Datensätze werden ignoriert.
Objekt SQL
Der OBJEKTSQL-Befehl definiert die Erzeugung von grafischen Objekten in der Zeichnung bei der Anbindung einer Datenbank. Er wird für jeden durch die GRUPPENSQL-Befehle erzeugten Knoten einmal aufgerufen. In diesem Beispiel findet der OBJEKTSQL-Befehl keine Verwendung, da aus der Datenbank keine grafischen Objekte erzeugt werden. Die folgende Beschreibung verdeutlicht daher nur die Befehlssyntax.
Es gibt nur einen OBJEKTSQL-Befehl für alle Ebenen.
Das Ergebnis kann aus folgenden Spalten bestehen:
| Typ | Es wird nur das erste Zeichen des Feldes ausgewertet. 0 oder „B“: Fügt einen Block in die Zeichnung ein. 1 „C“ oder „P“: Erzeugt ein Polygon aus allen gefundenen Datensätzen. Bei „C“ wird immer ein geschlossenes Polygon erzeugt. Der Voreinstellung ist 0 für Block. |
| ID | Die ID, mit der das Objekt am diesen Datensatz verknüpft wird. Das ist später bei der Synchronisation wichtig. Bei Typ 1 („Poly“) wird die ID des ersten gefundenen Datensatzes verwendet. Bei Typ 0 erhält jedes Objekt die ID des entsprechenden Datensatzes. |
| Name | Der Name der Blocks ist „$$DBOBJ.DWG“. Dieser Parameter entfällt bei Polygonen. |
| Farbe | Für die Farbe des Blocks oder Polygons gilt der Farbindex. Voreinstellung ist 7 für Weiß. Die Namen der Grundfarben bzw. die in Klammern stehenden Buchstaben „rot“ ®, „grün“ (g), „gelb“ (y), „cyan“ ©, „blau“ (b), „magenta“ (m) und „weiß“ (w); „weiss“ bzw. „schwarz“ werden ebenfalls erkannt. Groß- und Kleinschreibung wird dabei nicht unterschieden. Die Farbe „weiss“ bzw. „schwarz“ oder 7 wird in DATAflor CAD immer als Komplementärfarbe des Hintergrunds dargestellt. Bei den in Klammern stehenden Buchstaben reicht es, wenn das erste Zeichen übereinstimmt. „Yellow“ wird also als Gelb erkannt. |
| Faktor | Eine ganze oder reelle Zahl. Bei Blöcken ist dies der Faktor für die Skalierung. Voreinstellung ist 1,0. Bei Polygonen ist dies die Linienstärke. Voreinstellung ist 0.0 |
| Layer | Der Name des Layers, auf dem der Block oder das Polygon eingefügt wird. |
| X,Y,Z | Die Koordinaten für das Einfügen des Blocks bzw. für den Stützpunkt des Polygons. Voreinstellung ist jeweils 0.0. |
Sofern die Spalten in der Datenbank anders heißen, müssen sie im SQL-Befehl umbenannt werden:
| Schritt 1 | OBJEKTSQL: | SELECT ID, Art AS Typ, Name, Farbindex AS Farbe, Groesse AS Faktor, Rechts AS X, Hoch AS Y, Hoehe AS Z FROM KOORDINATEN WHERE PositionID=[POSITIONEN:PositionID] |
Liefert der OBJEKTSQL-Befehl bei Typ „Block“ (0) mehrere Ergebnisse, so werden mehrere Blöcke eingefügt. Liefert er bei Typ „Poly“ (1) mehrere Ergebnisse, so muss die Reihenfolge der Datensätze entweder durch ein entsprechendes „ORDER BY“ festgelegt werden, oder die Datensätze müssen vom Datenbanktreiber in der entsprechenden Reihenfolge geliefert werden.
Ein geschlossenes Polygon wird dann erzeugt, wenn die erste Koordinate als letzte noch einmal wiederholt wird oder der Typ „C“ angegeben wurde.
Um die Anforderungen an die Datenbankstruktur möglichst gering zu halten, kann dieser SQL-Befehl um Überschreibungen für die Defaults (Standards) ergänzt werden. Dies geschieht durch Anhängen der Überschreibungen in geschweiften Klammern am Ende des SQL-Befehls. Wird also z.B. der Typ nicht geliefert, soll aber 1 für „Poly“ sein, so lautet der Anhang: {Typ=1}
Wird der Name nicht geliefert, es soll aber der Block 3DBAUM.DWG eingefügt werden, so lautet der Anhang: {Name=3DBAUM.DWG}
Die Bezeichnung der erzeugten Objekte kann in einem Formatierungstext wie bei den AUSWAHLSQL- und GRUPPENSQL-Befehlen festgelegt werden. Wird der Formatierungstext leer gelassen, so findet eine Nummerierung im Nummernkreis des Objekt-Managers statt.
Bei der Voreinstellung DBOBJ.DWG im Namensfeld handelt es sich um einen bei DATAflor CAD mitgelieferten Block. Er enthält einen Kreis mit Durchmesser 1 und ein Kreuz.
Mengen SQL
Hier handelt es sich um zwei SQL-Befehle mit unterschiedlicher Bedeutung. MENGENSQL1 liest die Mengeneinheit aus bzw. definiert die Objekteigenschaft, welche in die Datenbank eingetragen werden soll. MENGENSQL2 schreibt die Menge in die Datenbank.
Für MENGENSQL1 stehen drei verschiedene Optionen zur Verfügung:

| SQL | Bei Auswahl SQL kann ein SQL-Befehl definiert werden, welcher die Mengeneinheit aus der Datenbank ausliest. Dies wird in dem Anwendungsbeispiel erläutert. |
| Formel {} | Mit der Auswahl Formel kann eine Objekteigenschaft oder eine Rechenoperation definiert werden, welche unabhängig von der in der Datenbank eingestellten Mengeneinheit in die Datenbanktabelle geschrieben wird. |
| Attribut {} | Mit der Auswahl Attribut kann im Massenbaum das zugeordnete Attribut eingestellt werden, welches in die Datenbanktabelle geschrieben wird. |
Nach der Auswahl einer der Optionen wird diese im Dialog eingetragen und darf nicht gelöscht werden. Der MENGENSQL1-Befehl mit der Option SQL sollte genau einen Datensatz als Ergebnis liefern. Alle weiteren gefundenen Datensätze werden ignoriert.
| Schritt 1 | MENGENSQL1: | SQL: SELECT Mengeneinheit FROM POSITIONEN WHERE PositionID=[POSITIONEN:PositionID] |
Die Mengeneinheit ist wichtig, damit DATAflor CAD weiß, welches Objektattribut in den Datensatz geschrieben werden soll. Bei m² ist dies die Fläche, bei m die Länge usw. Bei unbekannten Mengeneinheiten wird versucht, über die in der Datei UNITS.TBL beschriebenen Umrechnungen eine bekannte Mengeneinheit zu erhalten. Sollte die Tabelle keine Mengeneinheit enthalten, bleibt MENGENSQL1 leer und es wird immer die Menge mit den meisten Dimensionen eingetragen (bei Volumenobjekten m³, bei Flächenobjekten m² usw.).
Ausgenommen hiervon sind Objekte, denen ein Attribut mit der Bezeichnung DBMenge hinzugefügt wird (siehe GAEB-Schnittstelle > Arbeitsweise). Hierdurch können z.B. Umrechungen vorgenommen und dann dieses Ergebnis in die Datenbank eintragen werden. Bei diesen Objekten wird MENGENSQL1 nicht ausgewertet.
MENGENSQL2 ist für den Eintrag der Menge in die Tabelle notwendig, die mit MENGENSQL1 definiert wurde.
| Schritt 2 | MENGENSQL2: | UPDATE POSITIONEN SET Menge=[OBJECT:ATTRIBUTE] WHERE PositionID=[POSITIONEN:PositionID] | |
MENGENSQL2 wird jedes Mal aufgerufen, wenn innerhalb des Baums der Datenbankanbindung eine Veränderung stattfindet, wenn also Objekte hinzugefügt bzw. entfernt werden oder sich ein Zeichnungsobjekt verändert.
MENGENSQL2 muss nicht zwangsläufig zum Eintragen der Menge den Datensatz selektieren, der dem Knoten entspricht, der im Baum angezeigt wird.
Sollte MENGENSQL2 mehrere Datensätze als Ergebnis liefern, wird in allen Datensätzen der Mengeneintrag vorgenommen.
Beide MENGENSQL-Befehle dürfen nur eine Datenbankspalte selektieren.
Nach Fertigstellung der ODBS-Konfiguration wird die Konfigurationsdatei mit [OK] gespeichert und die Konfiguration erscheint anschließend in der Auswahl der Datenbankkonfigurationen für die Datenbankanbindung.